참고링크
- 이성욱 , 『Real MySQL』 , 위키북스
- hyungjoon6876.github.io/jlog/2018/07/20/btree.html
B-Tree 개념 정리
데이터베이스와 파일시스템에서 B-Tree를 많이 사용합니다. rdb 인덱스 관련해서 정리해보다가 일반적으로 B-Tree , B+-Tree 자료구조를 사용하는것을 알게되었습니다. B-Tree 자료 구조에 대해서 알아
hyungjoon6876.github.io
- 아직 1년도 안된 개발자라.. 틀린 내용이 있을 수 있습니다.
- 틀린 내용이나 지적할 부분이 있다면 robin00q@naver.com 혹은 댓글을 달아주세요.^_^
1. 인덱스란 무엇인가?
- 하나의 컬럼 값 혹은 여러개의 컬럼 값에 대해서, 저장된 주소를 저장하는 방식
- key(한 개 이상의 컬럼 값) : value(저장된 주소)
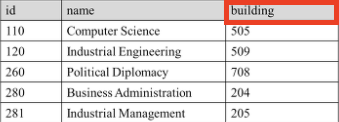
- 위와 같은 그림이 있다면, 추가적으로 하나의 인덱스를 하나 더 둬서 찾기 쉽게 하는 것이다.
- 예시로 building 컬럼에 대한 인덱스를 생성한다면 아래와 같이 생성하는 것이다.
| key (building 컬럼에 대해서 인덱스 테이블을 만들었다는 가정하에) | value (진짜 데이터의 주소값을 가리킴) |
| 204 | id 110에 대한 주소 |
| 205 | id 505에 대한 주소 |
| 505 | id 110에 대한 주소 |
| 509 | id 120에 대한 주소 |
| 708 | id 260에 대한 주소 |
- 인덱스 규칙
- 인덱스의 키 값은 정렬되어 있어야 한다.
- 장점 : SELECT 할 경우, 정렬되어 있기 때문에 빠르게 찾을 수 있다.
- 단점 : INSERT, DELETE, UPDATE 의 경우에, 정렬된 상태를 유지해야 하기 때문에 시간 복잡도가 더 걸린다.
- 인덱스의 키 값은 정렬되어 있어야 한다.
- 결론적으로, SELECT 성능을 얻고, INSERT, DELETE, UPDATE 성능을 희생시키는 것이다.
- 하지만 우리는 보통, SELECT를 INSERT / DELETE / UPDATE 보다 훨씬 많이 하기 때문에 성능상으로 이점을 얻을 수 있다.
2. B-TREE
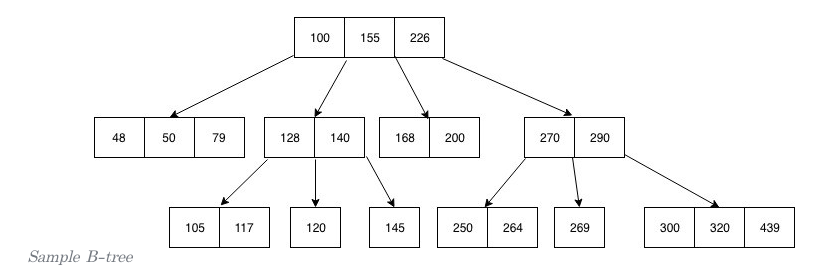
- 위의 그림과 같이 Balance 있게 정렬된 Tree 이다.
- 각 노드들은 실제 데이터를 가리키는 주소값을 갖고있다.
- 하나의 노드보다 작은 값은 좌측에, 큰 값은 우측을 가리키도록 한다.
- 이러한 INSERT 작업에서, INSERT 를 한 이후, 실제 디스크 I/O에 데이터를 저장 (디스크가 데이터 저장의 병목현상) 해야 한다.
- MySQL InnoDB 스토리지 엔진은 해당 데이터를 Insert Buffer Pool 에 저장한 뒤, 한번에 디스크 I/O 에 저장할 수 있도록 한다.
- DELETE 작업에서는, 삭제 마킹을 통해서 Index를 실제로 삭제하지않고, 추후 재활용하도록 하며,
- MySQL InnoDB 스토리지 엔진은 해당 데이터를 바로 삭제하지 않고, INSERT 와 마찬가지로 한번에 모아 디스크 I/O 에 반영한다.
3. 인덱스 키 값의 크기
MySQL 은 디스크에 데이터를 저장하는 기본 단위를 페이지라고 하며, 인덱스 역시 페이지 단위로 관리된다.
- MySQL InnoDB 스토리지 엔진은 페이지 크기가 16KB로 고정되어 있다.
- 만약, 내가 설정한 인덱스 크기가 16Byte, 자식 노드를 가리키는 주소의 크기가 12Byte 라면
- 16 * 1024 / (16+12) = 585로 하나의 페이지에 585 개의 인덱스가 저장될 수 있다.
- 위의 그림에서 [100, 155, 226] 이 저장되어 있는 루트를 볼 수 있는데, 해당 그림에서 최대 585개의 값이 저장될 수 있다는 뜻
- 인덱스 크기가 커질수록, 저장될 수 있는 인덱스의 개수가 줄어들고, depth 가 깊어진다.
- 만약, 내가 설정한 인덱스 크기가 16Byte, 자식 노드를 가리키는 주소의 크기가 12Byte 라면
4. Cardinality
- 모든 인덱스 가운데, 유니크 한 값의 개수
- Cardinality가 낮다 => 중복된 인덱스의 개수가 많다.
- Cardinality가 높다 => 중복된 인덱스의 개수가 적다.
- 훨씬 더 잘 설명된 글이 있습니다. 아래의 링크를 참고해주세요..
5. B-Tree Index Scan
- 인덱스 레인지 스캔
- 특정, 조건에 부합하는 레코드의 시작점을 찾은 뒤, 조건의 마지막까지 스캔하여 결과를 반환한다.
- 장점
- 범위내 스캔이므로 소량의 데이터에서는 빠르게 작동한다. (찾는 시간 없이, 범위 내에서만 스캔하면 되기 때문)
- 결과의 데이터는 정렬되어 있다. (인덱스는 정렬되어 있으니까)
- 단점
- 하나의 인덱스에서 데이터를 읽어오기 위해, 하나의 인덱스당 하나의 디스크 I/O 가 필요
- 따라서 처리하는 레코드가 20 ~ 25% 가 넘으면, 인덱스를 통한 SELECT 대신, 데이터를 직접 읽는 것이 더 빠르다.
- 하나의 인덱스에서 데이터를 읽어오기 위해, 하나의 인덱스당 하나의 디스크 I/O 가 필요
- 장점
- 특정, 조건에 부합하는 레코드의 시작점을 찾은 뒤, 조건의 마지막까지 스캔하여 결과를 반환한다.
- 인덱스 풀 스캔
- 말 그대로, 인덱스의 처음부터 끝까지 모두 읽는 방식이다.
- 테이블 전체 스캔보다 빠르게 동작함
- 쿼리가 인덱스 만으로 처리되는 경우 주로 사용한다.
- 인덱스 내에 없는 데이터를 필요로 하는 경우에는 테이블 스캔이 더 빠르다. (디스크 I/O 때문)
- 말 그대로, 인덱스의 처음부터 끝까지 모두 읽는 방식이다.
6. 번외 (HASH Index)
- 자료구조와 마찬가지로, 데이터 값에 대한 해쉬값을 찾아가서 데이터를 찾는 방식이다.
- 단건 조회에서는 인덱스 스캔보다 빠르나, 범위에 대한 스캔에서는 더 느리다.
'DataBase' 카테고리의 다른 글
| Transaction Isolation Level (격리수준) in MySQL (0) | 2020.11.30 |
|---|
